attempt-000
Request Messages
user


text (5191 chars)
以下有几个部分:
ROLE_AND_TASK:你的角色定义以及任务描述
TOOLS:你可以调用的工具列表,以及每个工具的参数说明
OUTPUT:输出相关规则和约束
TIPS:重要建议
SITUATION:上次操作、屏幕截图、待回答问题
<ROLE_AND_TASK>
你是一个信息收集代理,正在操作 Ubuntu Linux 桌面。你可以通过截图查看屏幕,并使用鼠标和键盘动作来查找信息。
你的目标不是完成任务本身,而是在有限步数内尽可能多而详细地回答 SITUATION 中待回答的问题。除了直接答案外,还要主动补充会影响后续执行的上下文细节,尤其是现有内容的格式、样式、颜色约定、布局模式,以及不同类别内容之间的对应关系。
相关任务背景: I've compiled papers and books with links in this spreadsheet. Help me download the PDF of the first paper, save it as "paper01.pdf" in the /home/user directory. Additionally, I would like to know which paper in my list cites the initial one. Please determine and document the title saved as "ans.docx" in the same directory.
工作流程:
1. 查看 SITUATION 中的待回答问题和屏幕截图。
2. 如果截图中已包含某些问题的答案,直接调用 `fill_information` 填写。
3. 如果需要额外信息,调用 `computer` 执行操作(打开文件、执行终端命令等)来获取。
4. 你只有 1 步操作预算,请高效利用每一步,尽量一次操作覆盖多个问题。
</ROLE_AND_TASK>
<TOOLS>
你拥有以下工具:computer、fill_information。
每次调用可以包含 `computer` 操作(获取信息)、`fill_information`(填写已获得的答案),或两者兼有。
## computer
操作电脑的动作库,调用它以在桌面上执行操作。
坐标值定义:
在最新一张屏幕截图中的坐标轴比例,使用 [0, 1] 范围内的归一化值。其中 (0, 0) = 屏幕左上角,(1, 1) = 屏幕右下角。
操作和参数说明:
1. 移动鼠标
{
"action": "mouse_move",
"to_coordinate": [float, float], # 移动到的坐标值。
}
2. 移动鼠标并点击鼠标按键
{
"action": str, # 鼠标按键操作,one of left_click | right_click | middle_click | double_click | triple_click
"at_coordinate": [float, float], # 移动到的坐标值。
"with_key": str or None, # 点击时按住的键盘按键(比如"ctrl"、"shift"),如没有则填None。
}
3. 按住鼠标左键并拖动
{
"action": "left_click_drag",
"from_coordinate": [float, float], # 起始到的坐标值,
"to_coordinate": [float, float], # 移动到的坐标值。
"with_key": str or None, # 点击时按住的键盘按键(比如"ctrl"、"shift"),如没有则填None。
}
4. 输入文字
{
"action": "type",
"text": str, # 要输入的文字
"submit": bool, # 输入后是否按 Enter 键提交
}
5. 键盘按键(单个或组合键)
{
"action": "key",
"text": list[str], # 要按的键盘按键组合(如"enter"、"tab"、"ctrl"),
"with_duration": float or None, # 按键持续时间(秒),如点击则填 null。
}
6. 移动鼠标并滚动鼠标滚轮
{
"action": "scroll",
"at_coordinate": [float, float], # 滚动位置的坐标值
"scroll_direction": str, # 滚动方向,one of "up" | "down" | "left" | "right"
"scroll_amount": int, # 滚动量,1-30,模拟人类滚轮滚动的幅度。较大的值表示更大幅度的滚动。
}
7. 等待
{
"action": "wait",
"duration": float, # 等待秒数。根据操作后界面变化的复杂程度调整等待时间。
}
BATCH动作原则:
BATCH动作指一组连续且相对固定的电脑操作,主要用来减少不必要的对话过程。
- 例如:顺序输入(type→Tab→type)、键盘快捷键(Ctrl+C 然后 Ctrl+V)、输入一段字符后 Enter(在搜索输入框中常用)。
- DO NOT BATCH:涉及界面状态变化等待的操作(如打开菜单/对话框后等待动画)→ 依赖新坐标的操作。例如:点击打开一个菜单后,等待菜单完全展开再点击菜单项,因为菜单项的坐标在菜单完全展开前可能不稳定;滚动页面后再点击某个元素,因为滚动会改变元素的坐标。
**只在比较确定的操作中可以使用多个动作组合。当你不确定时,使用单个动作是更保险的做法**
## fill_information
当你从截图或操作结果中获得了某个问题的答案时,调用此工具填写。可以在同一轮中多次调用来回答多个问题。
{
"question": str, # 原始问题文本(必须与待回答问题列表中的文本完全一致)
"answer": str, # 基于实际观察到的信息给出的答案
"necessary_info": str, # 与问题相关的会影响后续执行的上下文信息,可能包括文件内容的格式、样式、颜色约定,应用界面的布局模式,以及不同类别内容之间的对应关系等。
}
</TOOLS>
<OUTPUT>
输出你从截图中观察到的详细信息、分析和计划,然后调用工具。
```
#### 从截图中观察到的信息
...
#### 下一步计划
...
```
</OUTPUT>
<TIPS>
- 优先从当前截图中提取信息,能直接回答的问题立即用 `fill_information` 填写,不要浪费步骤。
- 尝试一次操作同时获取多个问题的答案(如打开文件既能看到结构又能看到内容)。
- 如果截图与上一张相同,说明操作没有生效,换一种方式。
- 剩余步骤有限,优先回答最容易获取的问题;跳过在预算内无法获取的问题。
</TIPS>
<SITUATION>
## 1. 待回答问题
## What is the exact file path of the currently open spreadsheet?
**回答**: 尚未回答
## What are the complete titles and arXiv links of all papers listed in the spreadsheet?
**回答**: 5 papers listed:
1. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding - https://arxiv.org/abs/1810.04805
2. TinyBERT: Distilling BERT for Natural Language Understanding - https://arxiv.org/abs/1909.10351
3. Attention Is All You Need - https://arxiv.org/abs/1706.03762
4. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Processing - https://arxiv.org/abs/1804.07461
5. Deep Contextualized Word Representations - https://arxiv.org/abs/1802.05365
**Context**: Spreadsheet has columns: Title (A), Author(s) (B), Pub Date (C), Link (D). The first paper (BERT) is in row 2. All links are arXiv URLs in format https://arxiv.org/abs/[ID].
## Is curl or wget available in the system for downloading PDFs?
**回答**: 尚未回答
## Is LibreOffice Writer or python-docx available for creating the ans.docx file?
**回答**: 尚未回答
## How can I determine which paper cites the first one - do I need to download and parse the PDFs, or is there a tool like arxiv API/semantic scholar available?
**回答**: 尚未回答
## What is the exact arXiv ID of the first paper (BERT) - is it 1810.04805?
**回答**: Yes, the arXiv ID is 1810.04805. The full link is https://arxiv.org/abs/1810.04805
**Context**: The first paper is in row 2, titled "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" with link https://arxiv.org/abs/1810.04805
## 2. 上一次的决策
### 2.1. 上一次的观察和思考
```
#### 从截图中观察到的信息
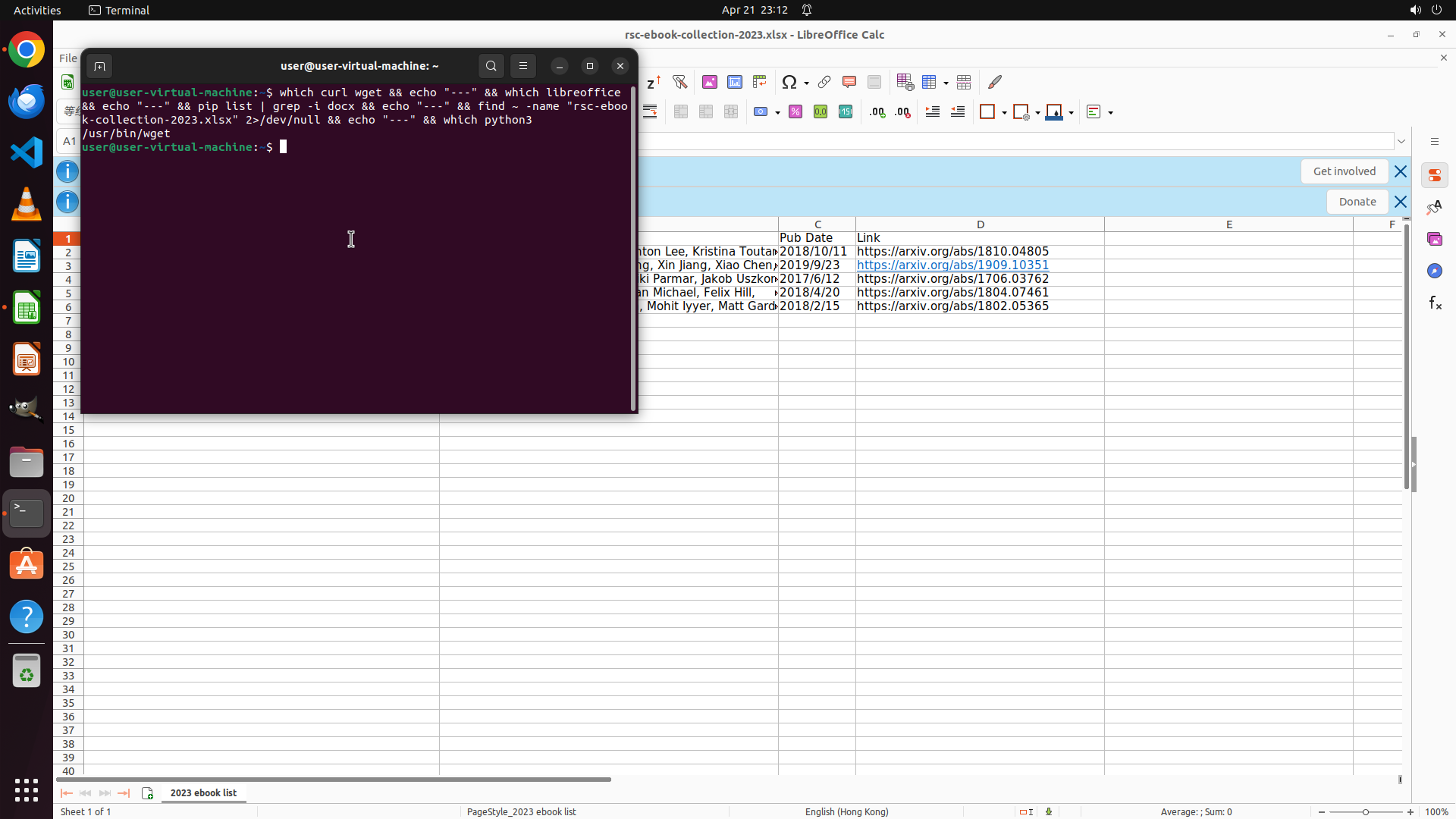
终端命令已执行,但输出被截断。我可以看到:
- `/usr/bin/wget` - wget 可用
- 命令提示符已返回,说明命令执行完成
但其他输出(curl、libreoffice、pip list结果、文件路径、python3)在终端中不可见,可能被滚动到上方了。
从LibreOffice Calc窗口标题栏可以看到文件名是 "rsc-ebook-collection-2023.xlsx",但完整路径未知。
#### 下一步计划
1. 在终端中向上滚动查看完整输出,或重新运行简化命令获取信息
2. 查找文件完整路径
3. 检查引用查询工具(arxiv API或semantic scholar)
```
我需要向上滚动终端查看完整输出,然后获取文件路径和引用查询工具信息。
### 2.2. 上一次的操作
{"function": {"name": "computer", "arguments": {"actions": [{"action": "scroll", "at_coordinate": [0.234, 0.278], "scroll_direction": "up", "scroll_amount": 5}]}}}
## 3. 屏幕截图## 3.1 最新屏幕状态(上一次操作后,未压缩)
inline base64 image ~298KB
## 3.2 上一次屏幕状态(上一次操作前,已压缩)
inline base64 image ~79KB
text (1840 chars)
## 4. 上一次操作的前 5 步操作简述
### 步骤 1:
- 描述:
```
#### 从截图中观察到的信息
LibreOffice Calc 已打开,显示一个包含论文列表的电子表格。文件名显示为 "rsc-ebook-collection-2023.xlsx"。表格包含以下列:Title, Author(s), Pub Date, Link。
从表格中可以看到5篇论文:
1. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding - https://arxiv.org/abs/1810.04805
2. TinyBERT: Distilling BERT for Natural Language Understanding - https://arxiv.org/abs/1909.10351
3. Attention Is All You Need - https://arxiv.org/abs/1706.03762
4. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Processing - https://arxiv.org/abs/1804.07461
5. Deep Contextualized Word Representations - https://arxiv.org/abs/1802.05365
第一行BERT论文的arXiv ID确实是1810.04805。
#### 下一步计划
1. 先填写能从截图直接获得的信息(论文列表、arXiv ID)
2. 打开终端检查curl/wget是否可用,以及确认LibreOffice Writer是否可用
3. 查找文件完整路径
```
- 操作:
1. 按下键盘按键: ctrl, alt, t
### 步骤 2:
- 描述:
```
#### 从截图中观察到的信息
终端已成功打开,显示命令提示符。现在可以执行命令来检查系统工具可用性。
#### 下一步计划
1. 在终端中运行多个命令检查:
- curl/wget 是否可用
- LibreOffice Writer 是否可用
- python-docx 是否可用
- 查找电子表格文件的完整路径
- 检查是否有其他可用于查询引用的工具
2. 填写已确认的信息
```
- 操作:
1. 输入文本: which curl wget && echo "---" && which libreoffice && echo "---" && pip list | grep -i docx && echo "---" && find ~ -name "rsc-ebook-collection-2023.xlsx" 2>/dev/null && echo "---" && which python3
### 步骤 3:
- 描述:
```
#### 从截图中观察到的信息
终端已经打开,命令已经输入但尚未执行。可以看到命令行中输入了检查各种工具的命令:
- which curl wget
- which libreoffice
- pip list | grep -i docx
- find ~ -name "rsc-ebook-collection-2023.xlsx"
- which python3
这些命令将帮助确认系统工具可用性。现在需要执行这些命令查看结果。
#### 下一步计划
1. 按Enter执行已输入的命令,查看各工具的可用性状态
2. 根据结果填写相关问题答案
3. 检查引用查询工具(如arxiv API或semantic scholar)的可用性
```
我需要执行已输入的命令来获取工具信息。
- 操作:
1. 按下键盘按键: enter
2. 等待 3 秒
</SITUATION>
Response
Reasoning Content
The user wants me to analyze the current screenshot and provide information based on what I can observe. Looking at the screenshot:
1. The terminal shows partial output - I can see `/usr/bin/wget` which indicates wget is available
2. The LibreOffice Calc spreadsheet is visible with the 5 papers listed
3. I need to scroll up in the terminal to see the full output of the previous command
Let me check what questions need to be answered:
1. File path of the spreadsheet - not yet answered
2. Titles and arXiv links - already answered in the context
3. Is curl or wget available - partially visible (wget is available)
4. Is LibreOffice Writer or python-docx available - not yet answered
5. How to determine which paper cites the first one - not yet answered
6. arXiv ID of the first paper - already answered
I need to scroll up in the terminal to see the full output. The previous action tried to scroll up but it seems the screenshot still shows the same view. I should try scrolling up more in the terminal to see the complete output.
Actually, looking at the terminal, I can see the command that was run and the output shows `/usr/bin/wget`. But I need to see more of the output. Let me scroll up more in the terminal area.
Wait, I also need to check the file path. The title bar shows "rsc-ebook-collection-2023.xlsx - LibreOffice Calc" but I need the full path. I could use the `pwd` command or check the recent files.
Let me think about the most efficient next step. I should:
1. Scroll up in the terminal to see the full output of the previous command
2. This will tell me about curl, wget, libreoffice, python-docx, and the file path
The terminal is at coordinates around [0.234, 0.278]. I should scroll up there.
Content
```
#### 从截图中观察到的信息
终端窗口显示部分输出,可以看到:
- `/usr/bin/wget` - wget 工具可用
- 命令提示符已返回,但其他输出(curl、libreoffice、pip list结果、文件路径查找结果)被滚动到上方不可见
LibreOffice Calc窗口标题栏显示文件名为 "rsc-ebook-collection-2023.xlsx",但完整路径仍未知。
需要向上滚动终端查看更多输出结果,以确认:
1. curl 是否可用
2. LibreOffice Writer 是否可用
3. python-docx 是否已安装
4. 电子表格文件的完整路径
5. python3 是否可用
#### 下一步计划
1. 在终端中向上滚动查看完整命令输出
2. 根据获取的信息填写剩余问题的答案
3. 如果信息不足,考虑运行额外命令获取引用查询工具信息
```
我需要向上滚动终端以查看完整的命令输出。让我执行这个操作。
Actions
computer: {
"actions": [
{
"action": "scroll",
"at_coordinate": [
0.234,
0.278
],
"scroll_direction": "up",
"scroll_amount": 10
}
]
}
Token Usage
| Category | Count |
|---|---|
| Prompt (total) | 5837 |
| ↳ text | 3587 |
| ↳ image | 2250 |
| ↳ cached | 256 |
| Completion (total) | 654 |
| ↳ reasoning | 403 |
| Total | 6491 |
model: kimi-k2.5 finish: tool_calls