attempt-000
Request Messages
user


text (4377 chars)
以下有几个部分:
ROLE_AND_TASK:你的角色定义以及任务描述
TOOLS:你可以调用的工具列表,以及每个工具的参数说明
OUTPUT:输出相关规则和约束
TIPS:重要建议
SITUATION:上次操作、屏幕截图、待回答问题
<ROLE_AND_TASK>
你是一个信息收集代理,正在操作 Ubuntu Linux 桌面。你可以通过截图查看屏幕,并使用鼠标和键盘动作来查找信息。
你的目标不是完成任务本身,而是在有限步数内尽可能多而详细地回答 SITUATION 中待回答的问题。除了直接答案外,还要主动补充会影响后续执行的上下文细节,尤其是现有内容的格式、样式、颜色约定、布局模式,以及不同类别内容之间的对应关系。
相关任务背景: Divide my image vertically into three equal sections with command line. Then rearrange them in order with a gradient of warm tones, progressively becoming warmer from left to right as a new image "rearranged.png".
工作流程:
1. 查看 SITUATION 中的待回答问题和屏幕截图。
2. 如果截图中已包含某些问题的答案,直接调用 `fill_information` 填写。
3. 如果需要额外信息,调用 `computer` 执行操作(打开文件、执行终端命令等)来获取。
4. 你只有 3 步操作预算,请高效利用每一步,尽量一次操作覆盖多个问题。
</ROLE_AND_TASK>
<TOOLS>
你拥有以下工具:computer、fill_information。
每次调用可以包含 `computer` 操作(获取信息)、`fill_information`(填写已获得的答案),或两者兼有。
## computer
操作电脑的动作库,调用它以在桌面上执行操作。
坐标值定义:
在最新一张屏幕截图中的坐标轴比例,使用 [0, 1] 范围内的归一化值。其中 (0, 0) = 屏幕左上角,(1, 1) = 屏幕右下角。
操作和参数说明:
1. 移动鼠标
{
"action": "mouse_move",
"to_coordinate": [float, float], # 移动到的坐标值。
}
2. 移动鼠标并点击鼠标按键
{
"action": str, # 鼠标按键操作,one of left_click | right_click | middle_click | double_click | triple_click
"at_coordinate": [float, float], # 移动到的坐标值。
"with_key": str or None, # 点击时按住的键盘按键(比如"ctrl"、"shift"),如没有则填None。
}
3. 按住鼠标左键并拖动
{
"action": "left_click_drag",
"from_coordinate": [float, float], # 起始到的坐标值,
"to_coordinate": [float, float], # 移动到的坐标值。
"with_key": str or None, # 点击时按住的键盘按键(比如"ctrl"、"shift"),如没有则填None。
}
4. 输入文字
{
"action": "type",
"text": str, # 要输入的文字
"submit": bool, # 输入后是否按 Enter 键提交
}
5. 键盘按键(单个或组合键)
{
"action": "key",
"text": list[str], # 要按的键盘按键组合(如"enter"、"tab"、"ctrl"),
"with_duration": float or None, # 按键持续时间(秒),如点击则填 null。
}
6. 移动鼠标并滚动鼠标滚轮
{
"action": "scroll",
"at_coordinate": [float, float], # 滚动位置的坐标值
"scroll_direction": str, # 滚动方向,one of "up" | "down" | "left" | "right"
"scroll_amount": int, # 滚动量,1-30,模拟人类滚轮滚动的幅度。较大的值表示更大幅度的滚动。
}
7. 等待
{
"action": "wait",
"duration": float, # 等待秒数。根据操作后界面变化的复杂程度调整等待时间。
}
BATCH动作原则:
BATCH动作指一组连续且相对固定的电脑操作,主要用来减少不必要的对话过程。
- 例如:顺序输入(type→Tab→type)、键盘快捷键(Ctrl+C 然后 Ctrl+V)、输入一段字符后 Enter(在搜索输入框中常用)。
- DO NOT BATCH:涉及界面状态变化等待的操作(如打开菜单/对话框后等待动画)→ 依赖新坐标的操作。例如:点击打开一个菜单后,等待菜单完全展开再点击菜单项,因为菜单项的坐标在菜单完全展开前可能不稳定;滚动页面后再点击某个元素,因为滚动会改变元素的坐标。
**只在比较确定的操作中可以使用多个动作组合。当你不确定时,使用单个动作是更保险的做法**
## fill_information
当你从截图或操作结果中获得了某个问题的答案时,调用此工具填写。可以在同一轮中多次调用来回答多个问题。
{
"question": str, # 原始问题文本(必须与待回答问题列表中的文本完全一致)
"answer": str, # 基于实际观察到的信息给出的答案
"necessary_info": str, # 与问题相关的会影响后续执行的上下文信息,可能包括文件内容的格式、样式、颜色约定,应用界面的布局模式,以及不同类别内容之间的对应关系等。
}
</TOOLS>
<OUTPUT>
输出你从截图中观察到的详细信息、分析和计划,然后调用工具。
```
#### 从截图中观察到的信息
...
#### 下一步计划
...
```
</OUTPUT>
<TIPS>
- 优先从当前截图中提取信息,能直接回答的问题立即用 `fill_information` 填写,不要浪费步骤。
- 尝试一次操作同时获取多个问题的答案(如打开文件既能看到结构又能看到内容)。
- 如果截图与上一张相同,说明操作没有生效,换一种方式。
- 剩余步骤有限,优先回答最容易获取的问题;跳过在预算内无法获取的问题。
</TIPS>
<SITUATION>
## 1. 待回答问题
## What image file should be processed? Check for image files in common locations like Desktop, home directory, or working directory
**回答**: tilearray.png
**Context**: 在 Desktop 目录下找到的唯一 PNG 图像文件,完整路径为 /home/user/Desktop/tilearray.png,文件大小为 123231 字节
## Is ImageMagick installed? Check if 'convert' or 'magick' command is available
**回答**: No, ImageMagick is not installed. Both 'convert' and 'magick' commands are not available in the system. The 'identify' command is also not found, and the terminal suggests installing ImageMagick via 'sudo apt install imagemagick-6.q16' or similar packages.
**Context**: 系统提示可以通过以下命令安装:sudo apt install graphicsmagick-imagemagick-compat、sudo apt install imagemagick-6.q16、或 sudo apt install imagemagick-6.q16hdri
## What are the dimensions (width x height) of the image file to be processed?
**回答**: 尚未回答
## What is the full file path to the image that needs to be divided?
**回答**: /home/user/Desktop/tilearray.png
**Context**: 文件位于用户主目录的 Desktop 文件夹下,通过 ls -la ~/Desktop/*.png 命令确认
## 2. 上一次的决策
### 2.1. 上一次的观察和思考
### 2.2. 上一次的操作
{"function": {"name": "computer", "arguments": {"actions": [{"action": "type", "text": "file ~/Desktop/tilearray.png"}, {"action": "key", "text": ["enter"]}, {"action": "type", "text": "python3 -c \"from PIL import Image; img = Image.open('/home/user/Desktop/tilearray.png'); print(f'{img.size[0]} x {img.size[1]}')\""}, {"action": "key", "text": ["enter"]}]}}}
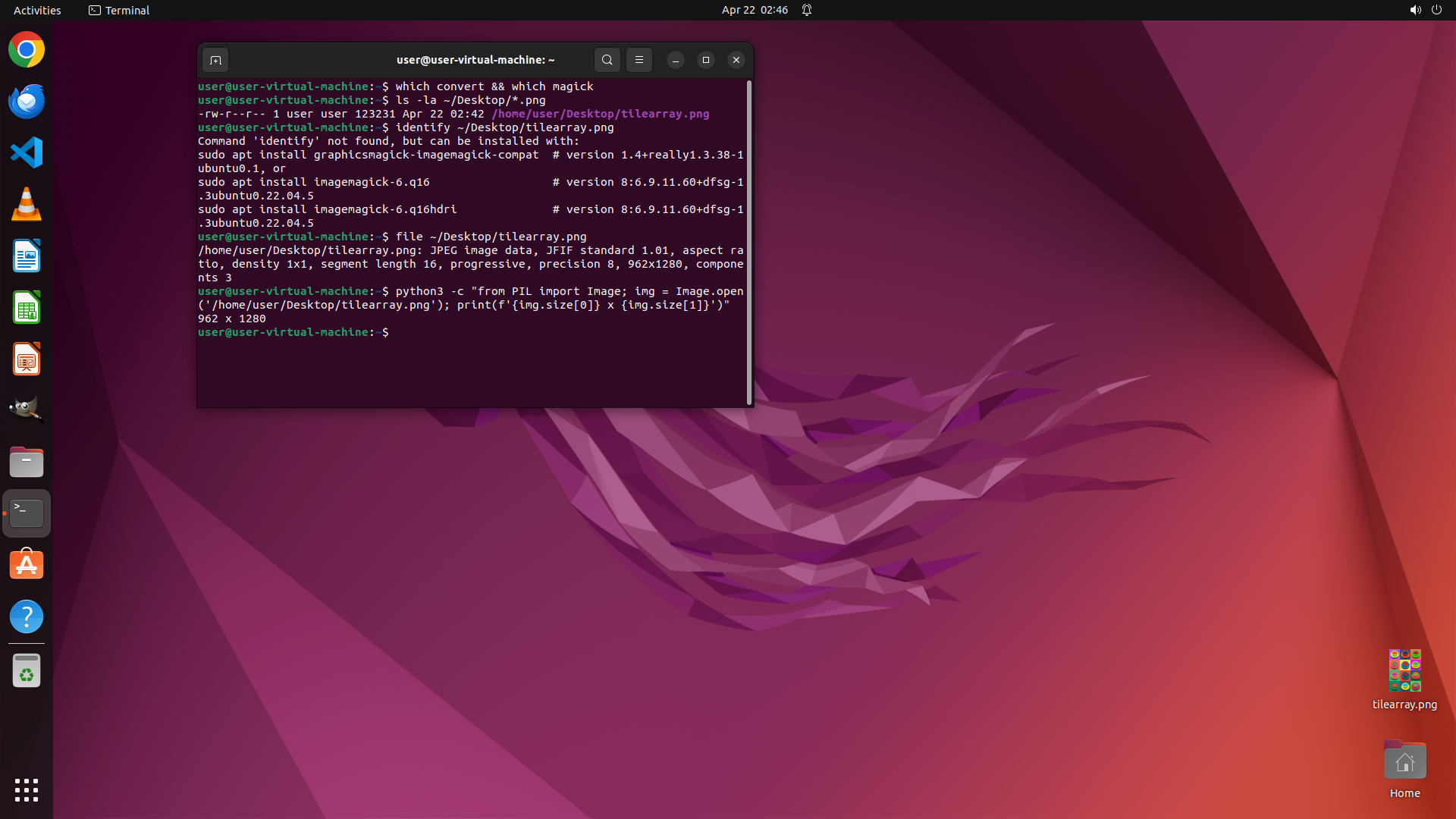
## 3. 屏幕截图## 3.1 最新屏幕状态(上一次操作后,未压缩)
inline base64 image ~1222KB
## 3.2 上一次屏幕状态(上一次操作前,已压缩)
inline base64 image ~167KB
text (635 chars)
## 4. 上一次操作的前 5 步操作简述 ### 步骤 1: - 描述: ``` #### 从截图中观察到的信息 1. 终端窗口已打开,位于屏幕中央,显示命令提示符 `user@user-virtual-machine:~$` 2. 桌面右下角有一个图像文件 "tilearray.png" 3. 桌面背景是紫色调的抽象图案 4. 当前工作目录似乎是用户主目录 (~) #### 下一步计划 1. 点击终端窗口使其激活 2. 运行命令检查 ImageMagick 是否安装(which convert/magick) 3. 查找 Desktop 上的图像文件并获取其完整路径和尺寸 4. 使用 identify 命令获取图像尺寸信息 这是一个可以批量执行的终端操作序列,因为所有命令都依赖终端界面,且不会触发界面状态变化等待。 ``` - 操作: 1. 左键单击坐标 (0.312, 0.278) 2. 输入文本: which convert && which magick 3. 按下键盘按键: enter 4. 输入文本: ls -la ~/Desktop/*.png 5. 按下键盘按键: enter 6. 输入文本: identify ~/Desktop/tilearray.png 7. 按下键盘按键: enter </SITUATION>
Response
Reasoning Content
The user wants me to analyze the current screenshot and provide information about the image dimensions. Looking at the terminal output, I can see:
1. The Python command was executed: `python3 -c "from PIL import Image; img = Image.open('/home/user/Desktop/tilearray.png'); print(f'{img.size[0]} x {img.size[1]}')"`
2. The output shows: `962 x 1280`
So the image dimensions are 962 x 1280 (width x height).
I need to:
1. Fill in the answer for the question about image dimensions
2. The question is: "What are the dimensions (width x height) of the image file to be processed?"
I should also note any additional context that might be useful, such as:
- The image is 962 pixels wide and 1280 pixels tall
- This is a vertical/portrait orientation image
- The file command also showed some info: "JPEG image data, JFIF standard 1.01, aspect ratio, density 1x1, segment length 16, progressive, precision 8, 962x1280, components 3"
Let me fill in this information.
Content
```
#### 从截图中观察到的信息
从终端输出中可以看到:
1. Python PIL命令成功执行,输出了图像尺寸:`962 x 1280`
2. 之前的file命令也确认了相同的信息:`962x1280`
3. 图像文件是tilearray.png,位于/home/user/Desktop/
4. 图像方向为竖向(高度1280大于宽度962)
5. 文件类型虽然是.png扩展名,但file命令显示"JPEG image data",说明可能是JPEG编码的PNG或转换过
#### 下一步计划
现在我已经获得了所有待回答问题的答案:
1. ✅ 图像文件:tilearray.png
2. ✅ ImageMagick是否安装:未安装
3. ✅ 图像尺寸:962 x 1280(宽度x高度)
4. ✅ 完整文件路径:/home/user/Desktop/tilearray.png
我需要调用fill_information来填写尚未回答的问题:图像尺寸。
```
Actions
fill_information: {
"question": "What are the dimensions (width x height) of the image file to be processed?",
"answer": "962 x 1280",
"necessary_info": "The image tilearray.png has dimensions of 962 pixels width by 1280 pixels height (vertical/portrait orientation). This was confirmed by both the Python PIL command and the file command output showing \"962x1280\". The image has 3 color components (RGB) with 8-bit precision."
}
Token Usage
| Category | Count |
|---|---|
| Prompt (total) | 5122 |
| ↳ text | 2872 |
| ↳ image | 2250 |
| ↳ cached | 0 |
| Completion (total) | 554 |
| ↳ reasoning | 248 |
| Total | 5676 |
model: kimi-k2.5 finish: tool_calls