attempt-000
Request Messages
user


text (6295 chars)
以下有几个部分:
ROLE_AND_TASK:你的角色定义以及任务描述
TOOLS:你可以调用的工具列表,以及每个工具的参数说明
OUTPUT:输出相关规则和约束
TIPS:重要建议
SITUATION:上次操作、屏幕截图、待回答问题
<ROLE_AND_TASK>
你是一个信息收集代理,正在操作 Ubuntu Linux 桌面。你可以通过截图查看屏幕,并使用鼠标和键盘动作来查找信息。
你的目标不是完成任务本身,而是在有限步数内尽可能多而详细地回答 SITUATION 中待回答的问题。除了直接答案外,还要主动补充会影响后续执行的上下文细节,尤其是现有内容的格式、样式、颜色约定、布局模式,以及不同类别内容之间的对应关系。
相关任务背景: Find the daily paper list on Huggingface and take down the meta information of papers on 1st March, 2024 in the opened .docx file. I have recorded two papers. Please conform to the format and complete others.
工作流程:
1. 查看 SITUATION 中的待回答问题和屏幕截图。
2. 如果截图中已包含某些问题的答案,直接调用 `fill_information` 填写。
3. 如果需要额外信息,调用 `computer` 执行操作(打开文件、执行终端命令等)来获取。
4. 你只有 2 步操作预算,请高效利用每一步,尽量一次操作覆盖多个问题。
</ROLE_AND_TASK>
<TOOLS>
你拥有以下工具:computer、fill_information。
每次调用可以包含 `computer` 操作(获取信息)、`fill_information`(填写已获得的答案),或两者兼有。
## computer
操作电脑的动作库,调用它以在桌面上执行操作。
坐标值定义:
在最新一张屏幕截图中的坐标轴比例,使用 [0, 1] 范围内的归一化值。其中 (0, 0) = 屏幕左上角,(1, 1) = 屏幕右下角。
操作和参数说明:
1. 移动鼠标
{
"action": "mouse_move",
"to_coordinate": [float, float], # 移动到的坐标值。
}
2. 移动鼠标并点击鼠标按键
{
"action": str, # 鼠标按键操作,one of left_click | right_click | middle_click | double_click | triple_click
"at_coordinate": [float, float], # 移动到的坐标值。
"with_key": str or None, # 点击时按住的键盘按键(比如"ctrl"、"shift"),如没有则填None。
}
3. 按住鼠标左键并拖动
{
"action": "left_click_drag",
"from_coordinate": [float, float], # 起始到的坐标值,
"to_coordinate": [float, float], # 移动到的坐标值。
"with_key": str or None, # 点击时按住的键盘按键(比如"ctrl"、"shift"),如没有则填None。
}
4. 输入文字
{
"action": "type",
"text": str, # 要输入的文字
"submit": bool, # 输入后是否按 Enter 键提交
}
5. 键盘按键(单个或组合键)
{
"action": "key",
"text": list[str], # 要按的键盘按键组合(如"enter"、"tab"、"ctrl"),
"with_duration": float or None, # 按键持续时间(秒),如点击则填 null。
}
6. 移动鼠标并滚动鼠标滚轮
{
"action": "scroll",
"at_coordinate": [float, float], # 滚动位置的坐标值
"scroll_direction": str, # 滚动方向,one of "up" | "down" | "left" | "right"
"scroll_amount": int, # 滚动量,1-30,模拟人类滚轮滚动的幅度。较大的值表示更大幅度的滚动。
}
7. 等待
{
"action": "wait",
"duration": float, # 等待秒数。根据操作后界面变化的复杂程度调整等待时间。
}
BATCH动作原则:
BATCH动作指一组连续且相对固定的电脑操作,主要用来减少不必要的对话过程。
- 例如:顺序输入(type→Tab→type)、键盘快捷键(Ctrl+C 然后 Ctrl+V)、输入一段字符后 Enter(在搜索输入框中常用)。
- DO NOT BATCH:涉及界面状态变化等待的操作(如打开菜单/对话框后等待动画)→ 依赖新坐标的操作。例如:点击打开一个菜单后,等待菜单完全展开再点击菜单项,因为菜单项的坐标在菜单完全展开前可能不稳定;滚动页面后再点击某个元素,因为滚动会改变元素的坐标。
**只在比较确定的操作中可以使用多个动作组合。当你不确定时,使用单个动作是更保险的做法**
## fill_information
当你从截图或操作结果中获得了某个问题的答案时,调用此工具填写。可以在同一轮中多次调用来回答多个问题。
{
"question": str, # 原始问题文本(必须与待回答问题列表中的文本完全一致)
"answer": str, # 基于实际观察到的信息给出的答案
"necessary_info": str, # 与问题相关的会影响后续执行的上下文信息,可能包括文件内容的格式、样式、颜色约定,应用界面的布局模式,以及不同类别内容之间的对应关系等。
}
</TOOLS>
<OUTPUT>
输出你从截图中观察到的详细信息、分析和计划,然后调用工具。
```
#### 从截图中观察到的信息
...
#### 下一步计划
...
```
</OUTPUT>
<TIPS>
- 优先从当前截图中提取信息,能直接回答的问题立即用 `fill_information` 填写,不要浪费步骤。
- 尝试一次操作同时获取多个问题的答案(如打开文件既能看到结构又能看到内容)。
- 如果截图与上一张相同,说明操作没有生效,换一种方式。
- 剩余步骤有限,优先回答最容易获取的问题;跳过在预算内无法获取的问题。
</TIPS>
<SITUATION>
## 1. 待回答问题
## LibreOffice Writer中打开的paper_reading_2024_03_01.docx文件的完整内容,特别是已记录的两篇论文的格式和元信息字段
**回答**: 第一篇论文(第一页):
- Title: StarCoder 2 and The Stack v2: The Next Generation(斜体)
- Authors: Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebase, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian McAuley, Han Hu, Torsten Scholak, Sebastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, Mostofa Patwary, Nima Tajbakhsh, Yacine Jernite, Carlos Muñoz Ferrandis, Lingming Zhang, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, Harm de Vries(斜体,逗号分隔)
- Abstract: The BigCode project introduces StarCoder2...
- Arxiv PDF: https://arxiv.org/pdf/2402.19173.pdf
第二篇论文(第二页):
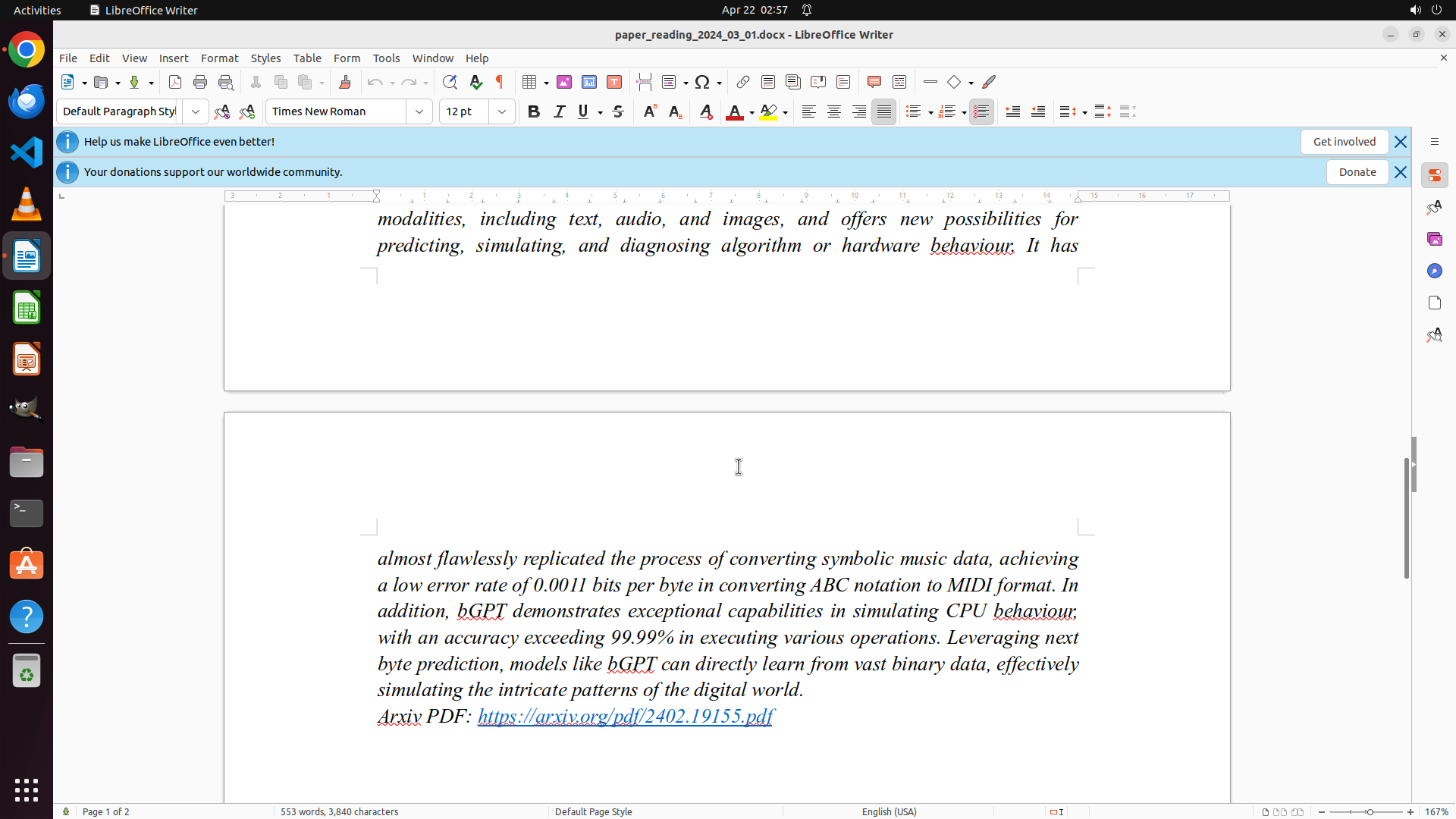
- Title: Beyond Language Models: Byte Models are Digital World Simulators(斜体)
- Authors: Shangda Wu, Xu Tan, Zili Wang, Rui Wang, Xiaobing Li, Maosong Sun(斜体,逗号分隔)
- Abstract: Traditional deep learning often overlooks bytes, the basic units of the digital world, where all forms of information and operations are encoded and manipulated in binary format. Inspired by the success of next token prediction in natural language processing, we introduce bGPT, a model with next byte prediction to simulate the digital world. bGPT matches specialized models in performance across various modalities, including text, audio, and images, and offers new possibilities for predicting, simulating, and diagnosing algorithm or hardware behaviour.(斜体)
**Context**: 格式约定:每篇论文包含Title、Authors、Abstract三个字段,标题和作者名使用斜体,多个作者用逗号分隔。文档共2页,已记录两篇论文。需要继续查找2024年3月1日Huggingface每日论文列表中的其他论文来补充。
## 系统中是否安装了Chrome浏览器以及版本
**回答**: Chrome浏览器已安装。从左侧任务栏可以看到Chrome的彩色圆形图标。
**Context**: 左侧任务栏有Chrome图标,表明已安装。需要进一步操作查看具体版本号。
## Huggingface每日论文页面的URL地址
**回答**: 尚未回答
## 文档第二页的内容是什么
**回答**: 第二页包含第二篇论文的信息:
- Title: Beyond Language Models: Byte Models are Digital World Simulators
- Authors: Shangda Wu, Xu Tan, Zili Wang, Rui Wang, Xiaobing Li, Maosong Sun
- Abstract: Traditional deep learning often overlooks bytes, the basic units of the digital world, where all forms of information and operations are encoded and manipulated in binary format. Inspired by the success of next token prediction in natural language processing, we introduce bGPT, a model with next byte prediction to simulate the digital world. bGPT matches specialized models in performance across various modalities, including text, audio, and images, and offers new possibilities for predicting, simulating, and diagnosing algorithm or hardware behaviour.
**Context**: 第二页论文格式与第一页一致:Title、Authors、Abstract三个字段,标题和作者使用斜体。这是关于bGPT模型的论文。
## 2. 上一次的决策
### 2.1. 上一次的观察和思考
### 2.2. 上一次的操作
{"function": {"name": "computer", "arguments": {"actions": [{"action": "scroll", "at_coordinate": [0.5, 0.556], "scroll_direction": "down", "scroll_amount": 5}]}}}
## 3. 屏幕截图## 3.1 最新屏幕状态(上一次操作后,未压缩)
inline base64 image ~404KB
## 3.2 上一次屏幕状态(上一次操作前,已压缩)
inline base64 image ~126KB
## 4. 上一次操作的前 5 步操作简述 ### 步骤 1: - 描述: - 操作: 1. 鼠标滚轮在坐标 (0.5, 0.556) 向下滚动,滚动量 10 ### 步骤 2: - 描述: - 操作: 1. 鼠标滚轮在坐标 (0.5, 0.556) 向下滚动,滚动量 5 </SITUATION>
Response
Reasoning Content
```
#### 从截图中观察到的信息
当前屏幕显示的是LibreOffice Writer打开的paper_reading_2024_03_01.docx文件,现在处于第二页。可以看到:
1. **第二页内容**(第二篇论文):
- Title: Beyond Language Models: Byte Models are Digital World Simulators(斜体)
- Authors: Shangda Wu, Xu Tan, Zili Wang, Rui Wang, Xiaobing Li, Maosong Sun(斜体,逗号分隔)
- Abstract: 关于bGPT模型的完整描述,包括"...almost flawlessly replicated the process of converting symbolic music data, achieving a low error rate of 0.0011 bits per byte in converting ABC notation to MIDI format. In addition, bGPT demonstrates exceptional capabilities in simulating CPU behaviour; with an accuracy exceeding 99.99% in executing various operations. Leveraging next byte prediction, models like bGPT can directly learn from vast binary data, effectively simulating the intricate patterns of the digital world."
- Arxiv PDF: https://arxiv.org/pdf/2402.19155.pdf(蓝色链接)
2. **格式约定**:
- Title使用斜体
- Authors使用斜体,多个作者用逗号分隔
- Abstract使用斜体
- Arxiv PDF使用蓝色链接格式
- 页面底部显示"Page 1 of 2",说明文档共2页
3. **Chrome浏览器**:左侧任务栏有Chrome图标,表明已安装
4. **需要获取的信息**:
- Huggingface每日论文页面的URL地址
- 第一页第一篇论文的完整内容(需要向上滚动查看)
#### 下一步计划
我需要:
1. 向上滚动查看第一页第一篇论文的完整内容
2. 打开Chrome浏览器访问Huggingface每日论文页面
3. 由于只有2步预算,我应该先滚动查看第一页内容,然后打开Chrome访问Huggingface
但考虑到效率,我可以先向上滚动查看第一页,获取第一篇论文的完整信息,然后再考虑打开Chrome。
```
我将向上滚动查看第一页第一篇论文的完整内容。
Actions
computer: {
"actions": [
{
"action": "scroll",
"at_coordinate": [
0.5,
0.556
],
"scroll_direction": "up",
"scroll_amount": 10
}
]
}
Token Usage
| Category | Count |
|---|---|
| Prompt (total) | 5522 |
| ↳ text | 3272 |
| ↳ image | 2250 |
| ↳ cached | 0 |
| Completion (total) | 493 |
| ↳ reasoning | 449 |
| Total | 6015 |
model: kimi-k2.5 finish: tool_calls